スプレッドシートでWebサイト上のデータを自動で取得して使いたいと思ったことはありませんか?
データの量が多いとコピペも大変だし、サイトを指定するだけとかだとすごく楽ですよね。
そんな問題を解決してくれる関数を今日は紹介していきます。
IMPORTHTML関数とは?
IMPORTHTML関数とは、Webページにある表やリストの内容を抽出できるGoogleスプレッドシート特有の関数です。Excelでは使えないので注意してください。
=IMPORTHTML(URL,クエリ,指数)
それぞれの引数について説明します。
- URL:抽出したい表やリストがあるWebぺージのこと
URLを「”」で囲み、「https://」から入力する
- クエリ:抽出したいものが表かリストかを指定するもの
以下のいずれかを入力する
・table→表(<table>タグ)の内容を抽出する
・list →リスト(<ol>タグや<ul>タグ)の内容を抽出する
- 指数:Webサイト上の何個目の表、もしくはリストを取得するのか指定するもの
ページの見た目ではなく、HTMLのソースコードにおける順序であることに注意する
ソースコードの順序って何?
IMPORTHTML関数の指数の部分を入力する際に、抽出したい表やリストは何番目なのか、してする数字が分からないという人はWebページのソースコードを表示させて調べましょう。
ちなみにソースコードはこのように表示されます。

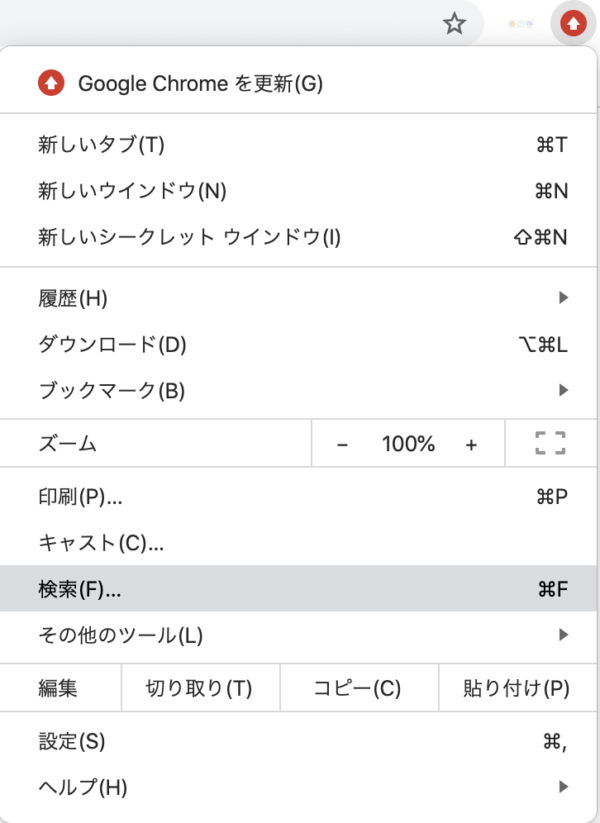
Google Chromeの場合、抽出したい表やリストのあるウェブページを開いて、
Mac:Command + Option + U
Windows:Ctrl + U
を押すとソースコードを表示することが出来ます。
もしくは、メニューの表示>開発/管理>ソースを表示でも同じことができます。
さらに検索ボックス(Command + F / Ctrl + F)を表示させて、<table>タグや<ul>タグ<ol>タグを検索すると簡単に調べることが出来ます。
IMPORTHTML関数の使い方
では実際に使ってみましょう。
①データの抽出方法
関数を打ち込みます。
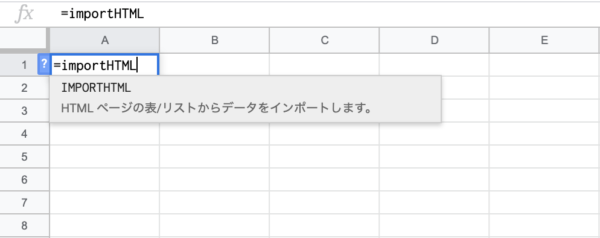
1つ目の引数「URL」を入力します。
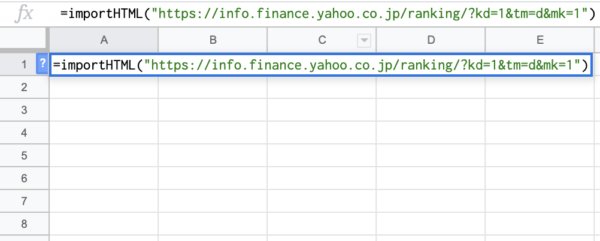
次に2つ目の引数「クエリ」を入力します。今回は「table」を使い表の内容を抽出しました。
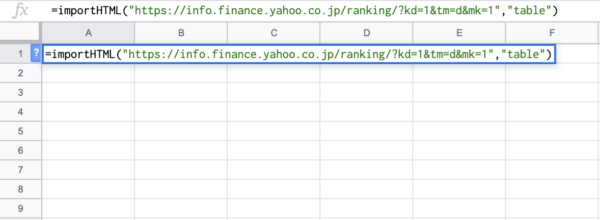
最後に3つ目の引数「指数」を入力します。
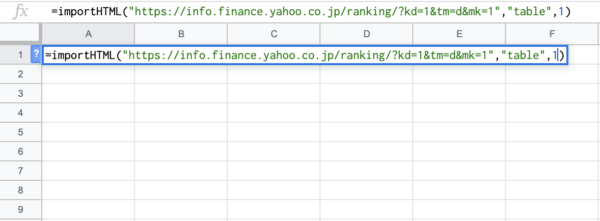
入力を終えたらEnterキーを押します。すると……
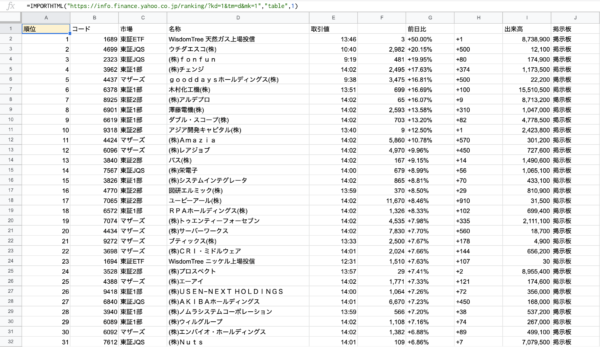
このように見事にサイトの表の内容が反映されました。
②データの編集方法
IMPORTHTML関数で抽出したテキストはそのまま編集すると以下のようにエラーが起こります。
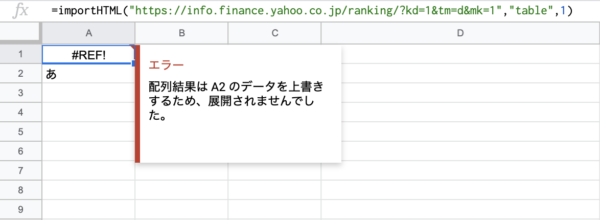
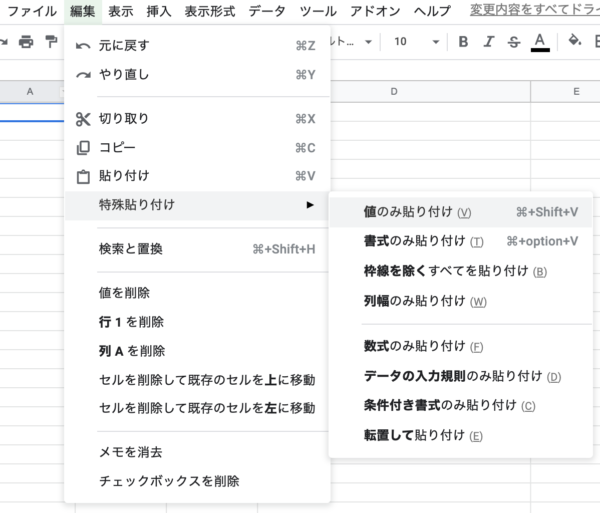
テキストを編集するためにはIMPORTHTML関数の結果があるセル範囲をコピーして、「値のみ貼り付け」をしましょう。そうすることで関数の結果ではなく、普通のデータとして扱うことができます。
実際に使ってみた!
実際にIMPORTHTML関数を株価の取得に便利そうだと思ったのでYahoo!JAPANのファイナンスサイト(https://finance.yahoo.co.jp/)を使って試してみました。
まずは株式ランキングの表を抽出しました。
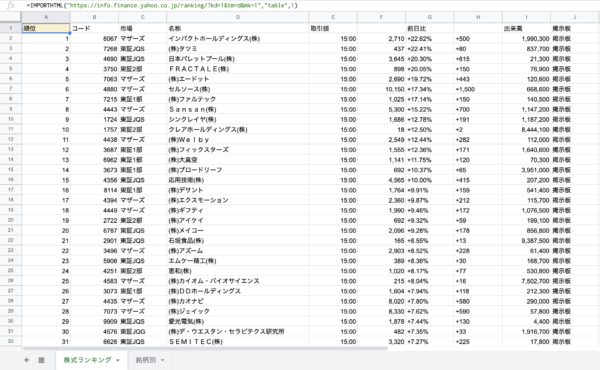
1つのセルに関数を打ち込んだだけで、これだけの項目が50位まで一瞬で表示されました。とても便利ですね!
さらに銘柄別でもデータを抽出してみました。
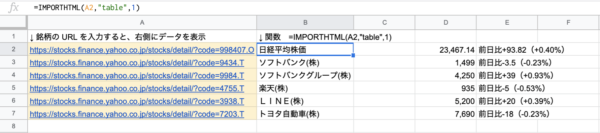
B列に関数を入力して、A列に銘柄のURLを入力するとデータが抽出されるようになっています。こちらも知りたい銘柄のデータだけを一瞬で抽出することができます。
使ってみて感じたこと
【メリット】
- セルに関数を入れるだけでデータを一瞬で抽出してくれるので、時間がかからない
- Webのデータをそのまま抽出してくれるので、ミスが起こらない
- Webサイトが更新されれば抽出データも自動で更新される
【デメリット】
- 関数を打ち込む際の引数「指数」がわかりにくい
- IMPORTHTMLと打つのが長い、大変
ただデメリットの解決案として、「指数」がわかりにくいのは何個か試していくと当たるし、使っていけば慣れてわかるようになると感じました。
また、関数の名前に関しても「=IMP」まで打つと候補に出てくるので全て打つ必要はなさそうです。
スプレッドシートでのデータ集計、手作業で続けていませんか?
Robomaを使えば、60以上の広告媒体のデータ収集からレポート作成まで自動化。毎週の手入力から解放されます。
IMPORTHTML関数のまとめ
Webページから表やリストを自動取得する方法をご紹介しました。
一瞬で大量のデータを抽出することが出来て、とても便利な機能ですよね。
さらに、抽出したデータをピボットテーブルなどで集計すると、欲しい情報が簡単に手に入るかもしれません。
NEXT STEP
スプレッドシートの手作業、
もっと効率的な方法があります。
Robomaは、Google・Meta・Yahoo!など60以上の広告媒体のデータを自動で収集し、
BigQuery + Looker Studio で可視化する広告データインフラツールです。
スプレッドシートでの手作業を卒業して、データ分析に集中しませんか?

\ まずはお気軽にお問い合わせください /
無料トライアル・資料請求はこちら