Googleスプレッドシートで「Webサイト上にあるデータを取ってきたい」ということはありませんか?
数行のデータであればコピペで済むかもしれませんが、大量のデータとなるとそうはいきません。
そこで役に立つのが「IMPORTXML関数」です。
今回は、そのIMPORTXML関数についてご紹介していきたいと思います。
IMPORTXML関数とは?
IMPORTXML関数とは、GoogleスプレッドシートでWebサイト上にあるデータを簡単に取得できる関数です。
Web上のデータを収集することをスクレイピングと言いますが、本格的なスクレイピングはプログラミングの技術が必要なのです。しかし、この関数を使うことで簡単なスクレイピングができるのです。
IMPORTXML関数の使い方
=IMPORTXML(”URL” , ”XPath”)
=IMPORTXML(”https://roboma.io/blog/”, ”//h1[@class=’h2 entry-title’]”)
それぞれの引数についてご説明していきます。
・URL:データを取得したいWebサイトのURL
・XPath:Webサイト内の取得したいデータを指定するもの
IMPORTXML関数の使い方の具体例
それでは実際にIMPORTXML関数の使い方を見ていきましょう。
今回はこのサイトのブログタイトルを取得したいと思います。
- XPathを取得する
まず、データを取得したいWebサイトをGoogle Chromeで開きます。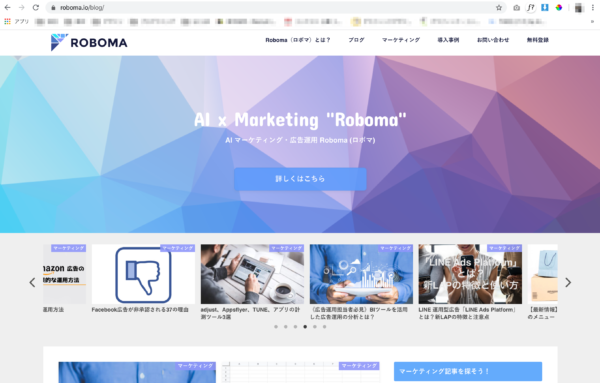
次にデベロッパーツールを開きます。
Google Chromeで右上のボタンをクリックします。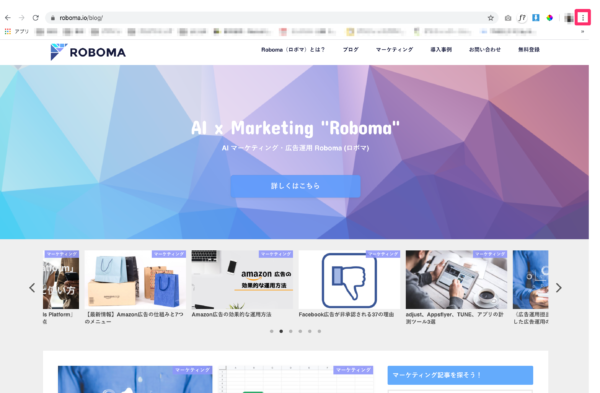
その他のツール>デベロッパーツールを選択します。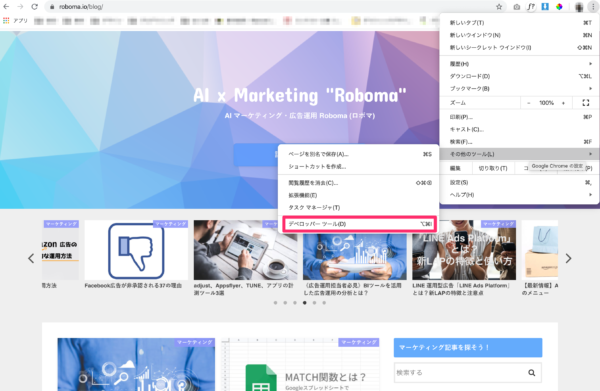
左上の矢印ボタンをクリックします。
取得したいページの要素をクリックして、出てきたコードを右クリックします。
Copy>Copy XPathとクリックして、XPathをコピーします。
ちなみに、XPath とは HTML 内でその要素がどの階層に存在しているかを指定する「住所」のようなものです。

- Googleスプレッドシートに入力する
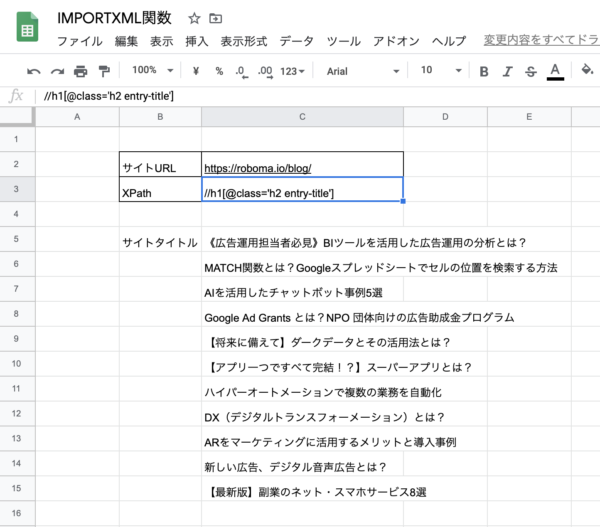
サイトURLと先ほどコピーしたXPathを入力して実行します。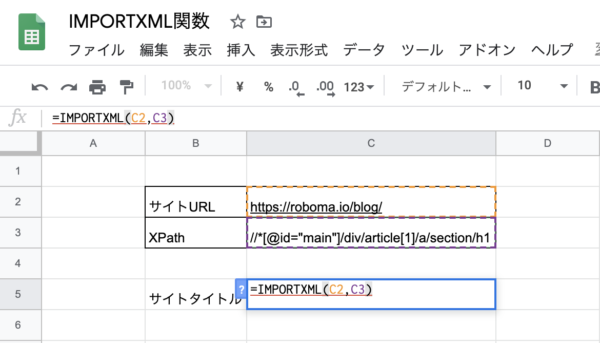
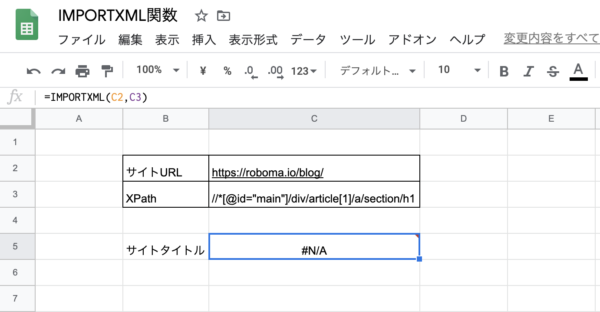 すると、エラーが出てしまいました。
すると、エラーが出てしまいました。
ブログの構成が難しいみたいです。
なので、以下のように書き換えてみます。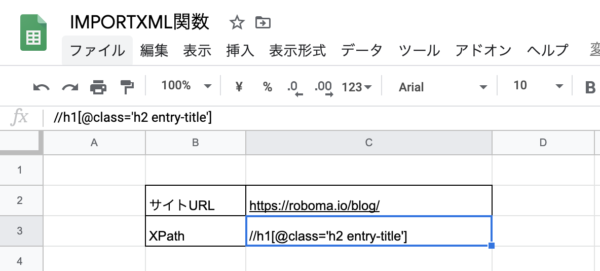
XPathの書き方についてはこちらを参考にしてみてください。
- 実行する
すると以下のように、指定したWebサイトのページにあるブログタイトルのデータを取得することができました。
詳しくは、Googleヘルプページでもご確認いただけます。
https://support.google.com/docs/answer/3093342?hl=ja
スプレッドシートでのデータ集計、手作業で続けていませんか?
Robomaを使えば、60以上の広告媒体のデータ収集からレポート作成まで自動化。毎週の手入力から解放されます。
IMPORTXML関数のまとめ
いかがでしたでしょうか。
今回ご紹介したIMPORTXML関数を使うことで、外部サイトのデータを自動取得し、競合調査などの業務効率化が実現できます。
是非使ってみてください。
NEXT STEP
スプレッドシートの手作業、
もっと効率的な方法があります。
Robomaは、Google・Meta・Yahoo!など60以上の広告媒体のデータを自動で収集し、
BigQuery + Looker Studio で可視化する広告データインフラツールです。
スプレッドシートでの手作業を卒業して、データ分析に集中しませんか?

\ まずはお気軽にお問い合わせください /
無料トライアル・資料請求はこちら